Case Study · Production-Browser-Automation
Multi-Process Browser-Automation Framework
Ein Framework für parallele, fehlertolerante Browser-Workflows: race-safe Worker-Koordination, Cross-Process Crash-Bridge und vollständige Operator-UX über Streamlit.
- 0
- Zeilen Production-Python
- 0+
- pytest-Tests, CI auf jedem Push
- 0
- Module, keine zirkulären Imports
Die Herausforderung
Ein Privatkunde benötigte ein dauerhaft betriebsbereites Backend für browserbasierte Automatisierungs-Workflows. Die Anforderungen waren von Anfang an vom Engineering her gedacht, nicht vom Featureset:
- Mehrere parallele Browser-Sessions, sauber voneinander isoliert.
- Subprocess-Architektur, ein Crash in einer Session darf andere nicht mitreißen, und ein hängender Workflow darf den ganzen Prozessbaum nicht blockieren.
- Vollständige Beobachtbarkeit, jeder Phasen-Übergang protokolliert seinen Status, jeder Crash trägt einen eindeutigen Phasen-Marker.
- Operator-UX über ein Dashboard statt über die CLI, der Endnutzer ist der Kunde, nicht der Developer.
- 100 % Type-Hinting, klare Layer-Trennung, vollständiges pytest-Setup mit GitHub-Actions-CI ab Tag eins.
Trivial ist das auf Windows nicht: parallele Chrome-Instanzen sind ein Minenfeld aus Race-Conditions (Port-Kollisionen bei dynamischer CDP-Allokation, Profil-Locks im User-Data-Dir, Zombie-Prozesse beim Streamlit-Restart). Und ein Subprocess, der stirbt, bevor sein eigener Crash-Handler überhaupt laufen kann, bedeutet ohne Schutzmechanismus eine stumm verlorene Fehlermeldung, exakt die Klasse Bug, die in der Produktion sechs Wochen unentdeckt bleibt.
Die Umsetzung
Das Resultat ist eine 17.461-LOC Python-Codebase in 25 sauber modularisierten Files, durchgehend Type-annotiert, organisiert in drei klar entkoppelten Layern:
Presentation → Streamlit-UI
Control → Scheduler + CLI-Orchestrator
Execution → Browser-Worker (als Subprocesses)Cross-Layer-Kommunikation läuft ausschließlich über SQLite und atomar geschriebene JSON-Files; kein Worker importiert je einen anderen.
- Race-Safe Multi-Worker-Koordination. Bei N parallelen asyncio-Tasks teilen sich die Worker einen gemeinsamen
asyncio.Lock-basierten Round-Robin: nur ein Worker führt zur Zeit den teuren Discovery-Schritt aus, die übrigen warten am Lock und übernehmen das Resultat aus einem Shared-Dict. Halbiert ausgehenden Output ohne Geschwindigkeitsverlust und vermeidet, dass alle Worker dieselbe Operation parallel duplizieren. - Best-Result-Aggregation mit Coordinated Cancellation. Sobald ein Worker das Zielergebnis erreicht hat, feuert eine
asyncio.Eventund ein Watchdog-Task rufttask.cancel()auf alle Geschwister-Tasks. SaubereCancelledError-Propagation statt Polling. Zusätzlich unterdrückt ein klassen-globaler_completed_jobs-Set spätere Reports aus den abgebrochenen Tasks, kein Notification-Spam, selbst wenn 10 Geschwister gleichzeitig ihren Cleanup-Pfad durchlaufen. - Subprocess-Isolation auf Windows-Niveau. Jeder Worker bekommt eine vollständig isolierte Chrome-Instanz: race-safe Port-Allokation via Socket-Bind (
_PortLockhält den Port reserviert, bis Chrome ihn übernimmt, kein TOCTOU-Race), eigenes User-Data-Dir (chrome_<uuid>), eigener Crash-Dump-Pfad, eigene CDP-Session. Keine geteilten Ressourcen, keine Lock-Konflikte zwischen parallelen Sessions, kein Übergreifen von Browser-State. - CDP-basierte Auth-Konfiguration. Statt einer klassischen Manifest-V2-Browser-Extension läuft die Auth-Konfiguration direkt über Chrome DevTools Protocol via
Fetch.authRequired. Auth-Events propagieren automatisch auf Popup-Pages über einencontext.on("page", ...)-Handler. Eine schlanke Klasse ersetzt den traditionellen Extension-Workaround und kommt mit deutlich weniger Surface-Area aus. - Cross-Process Crash-File-Bridge. Worker laufen als Subprocesses, vom Scheduler über
subprocess.Popenangeworfen. Bei einem Crash schreibt der Subprocess eine strukturierte JSON-Datei nachdata/crashes/job_<id>_<ts>.jsonUND versucht parallel eine direkte Telegram-Benachrichtigung. Der Scheduler liest die Datei nach Subprocess-Exit zurück, dedupliziert mit der bereits abgesetzten Notification, ergänzt fehlende Meldungen oder räumt die Datei stillschweigend auf, wenn alles bereits gemeldet wurde. Ein globalersys.excepthookals Last-Line-of-Defence garantiert: kein Crash geht verloren, selbst wenn der Subprocess so früh stirbt, dass der eigene Crash-Handler nicht mehr läuft. - Per-Phase-Timeouts mit Live-Phase-Tracking. Jede Workflow-Phase läuft in einem dedizierten
asyncio.timeout()-Block; jede Phase aktualisiert ein zentrales Context-Objekt mit dem aktuellen Sub-Step. Bei Crash steht im Telegram-Report exakt, in welcher Phase welcher Worker scheiterte, nicht „irgendwo in main()", sondern „4/6 add_step: konkretes UI-Element X". Debugging-Zeit fällt von „erstmal Logs durchsuchen" auf „direkt zur fraglichen Funktion". - Typisierte Fehler-Hierarchie + Swarm-Deduplication. Eine eigene Exception-Klasse pro Failure-Modus (
ProxyError,NavigateError,SessionExpiredError, …), jede mit eigener Recovery-Politik (Browser schließen vs. offen lassen, Retry mit anderem Proxy, Hard-Fail). Wenn 10 Worker parallel mit demselben Root-Cause crashen, gruppiertreport_grouped_errorsdie Meldungen nach (Exception-Typ, erstem Stackframe) und sendet eine einzelne aggregierte Telegram-Nachricht mit Worker-IDs und betroffenen Phasen, keine 10 redundanten Pings. - SQLite mit WAL + BEGIN IMMEDIATE für Race-Sicherheit. Counter und State in den Tabellen werden in Read-Modify-Write-Transaktionen aktualisiert. Bei N parallelen Workern, die gleichzeitig Counter erhöhen, würde naive UPDATE-Counter-Logik den Counter um 1 statt N inkrementieren,
BEGIN IMMEDIATEserialisiert die Updates korrekt und verhindert die Race auf SQLite-Ebene, bevor sie überhaupt Python erreicht. Plus WAL-Modus + 64 MB Cache + 256 MB mmap für Read-Performance unter parallelem Schreibdruck. Auto-Migrationen beim ersten Connect, mit pytest-Tests, die jede Migration einzeln verifizieren. - Atomic-File-IPC. Sämtliche Inter-Process State-Files (Job-Status-Snapshots, Live-State, Run-Reports) werden atomar geschrieben,
.tmpschreiben, dannos.rename(). Kein Worker liest je eine halb-geschriebene JSON-Datei, selbst unter konkurrierendem Zugriff aus mehreren Subprocesses. POSIX-Semantik, funktioniert auch auf Windows seitPath.replace(). - Datums-versionierte Logs.
logs/<DD-MM-YYYY>/{chrome,traces,screenshots,…}/, jede Phase jedes Workers erzeugt klar zugeordnete Artefakte (Chrome-Stdout, Playwright-Trace, Failure-Screenshot). Bei einem Production-Issue findet man perls logs/23-03-2026/screenshots/in fünf Sekunden die genaue Failure-Phase jedes betroffenen Workers, plus den vollständigen Playwright-Trace zum Replay im Browser-Trace-Viewer. - Streamlit-Operations-UI mit Windows-Hard-Cleanup. Multi-Page-Dashboard mit Service-Lifecycle (Start/Stop/Restart aller Subsysteme), DB-CRUD, Live-Logs, EN/IT-Lokalisierung über 300+ String-Pairs. Streamlit ist auf Windows heikel, Process-Tree-Cleanup wird beim Shutdown nicht garantiert, Kinder werden zu Zombies. Gelöst über ein Windows Job Object mit
JOB_OBJECT_LIMIT_KILL_ON_JOB_CLOSE: jeder Subprocess wird beim Spawn dem Job-Handle zugewiesen, beim Streamlit-Exit terminiert das OS automatisch alle Kinder kaskadierend. Funktioniert auch bei Hard-Kill via Task-Manager, keine übriggebliebenen Browser-Prozesse mehr. - Zentralisierter Telegram-Reporter. Eine einzige
ErrorReporter-Klasse als Single-Entry-Point für sämtliche Notifications. Fire-and-forget by Contract: wirft nie eine Exception, blockiert nie länger als der HTTP-Roundtrip, fällt bei Verbindungsfehlern (Windows 10054 ConnectionReset, …) leise ab und retryt mit frischer Session. Direktverbindung ohne Proxy (session.trust_env = False), damit System-Proxy-Vars die Reports nicht silent killen, plus globale Suppression-Logik gegen Notification-Storms.
Engineering Highlights & Fail-Safe-Architektur
Zuverlässigkeit war absolut nicht verhandelbar, das System läuft 24/7 unbeaufsichtigt und der Endnutzer ist kein Developer:
- 9 pytest-Test-Suites mit GitHub-Actions-CI. Database-Migrations (idempotent, mehrfach ausführbar), Error-Reporter (260+ Tests inklusive Suppression-Logik und Crash-File-Roundtrip), Coordination-Patterns, Proxy-Layer, Shared-Helpers, Config-Resolution, alles automatisch auf jedem Push gegen Ubuntu Python 3.13 validiert. Migrations-Bugs werden vor dem Deploy abgefangen, nicht zur Laufzeit.
- Strikte Layer-Trennung ohne zirkuläre Imports. Presentation-Layer importiert nur Control-Layer; Control-Layer importiert nur Execution-Layer + Utils. Jeder Subprocess kann standalone hochgefahren werden, ohne dass Streamlit überhaupt installiert sein muss, relevant für CI-Runs und Debugging-Sessions ohne UI-Overhead.
- Singleton-Path-Resolution. Eine
PATHS-Singleton-Klasse mit Auto-Root-Detection (sucht aufwärts nach Marker-Files wie.git,.env,requirements.txt) und automatischer Verzeichnis-Erstellung bei Property-Access. Code aus jedem beliebigen Working-Directory aufgerufen findet konsistent dieselben absoluten Pfade, kein einzigesos.path.join(os.path.dirname(__file__), …)in der ganzen Codebase. - Dataclass-First Domain-Model. Alle Workflow-Inputs und -Outputs sind Dataclasses mit Type-Hints, Validation-Logik und sauberen
from_dict/to_dict-Roundtrips. Saubere Schnittstellen zwischen Layern, IDE-Autocomplete funktioniert, Refactorings ziehen Compile-Time-Fehler nach sich statt Runtime-AttributeErrors. - Test-First für IPC-kritische Komponenten. Crash-File-Bridge, Suppression-Gate und Aggregator-Logik sind die riskantesten Stellen, sie laufen genau dann, wenn alles andere kaputt geht. Entsprechend dicht ist die Test-Suite: ein eigenes
_clear_*-Fixture-Pattern resettet klassen-globalen State zwischen Tests, jeder Edge-Case (Subprocess crashed VOR Crash-File-Write, Crash-File ohne Telegram-Flag, Telegram nach Crash-File, beides parallel) hat einen expliziten Test-Case. - Dependency-Injection-Layer für Tests. Jede externe Abhängigkeit (DB, Telegram, Proxy-Provider, Filesystem) sitzt hinter einer schmalen Schnittstelle, die im Testbetrieb durch ein In-Memory-Pendant ersetzt werden kann. Die SQLite-Tests laufen aber gegen eine echte SQLite-DB im pytest-
tmp_path, nicht gegen einen Mock, Migrations-Bugs würden Mocks systematisch nicht aufdecken.
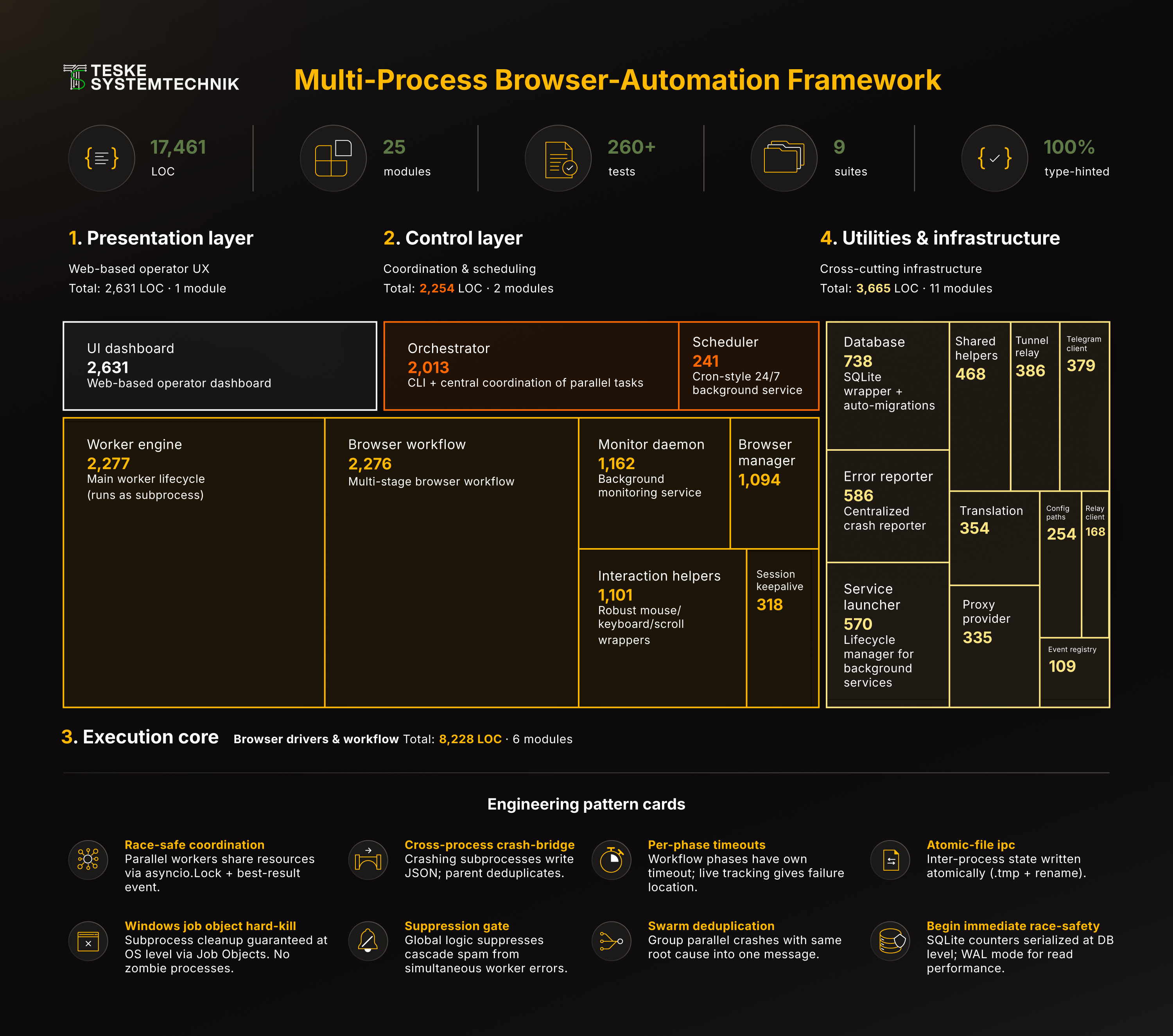
Volumen-Aufschlüsselung der gesamten Codebase über Presentation-, Control-, Execution-Core- und Utility-Layer, der Execution-Core (8.228 LOC) dominiert visuell als größter Block, die Utility-Schicht zeigt die Modularität in 11 kleinen Helper-Modulen.
Das Ergebnis
- 17.461 LOC Production-Python in 25 sauber modularisierten Files, klare Layer-Trennung, keine zirkulären Imports, jede Stage standalone lauffähig.
- 260+ pytest-Tests mit GitHub-Actions-CI auf jedem Push, Migrations-Bugs, IPC-Race-Conditions und Suppression-Logik werden vor dem Deploy abgefangen.
- Cross-Process Crash-Bridge, kein Crash geht verloren, selbst bei Subprocess-Tod vor dem eigenen Crash-Handler.
- Race-safe Coordination zwischen N parallelen Browser-Workern auf Windows, keine Port-Kollisionen, keine Profil-Locks, keine Zombie-Prozesse beim Shutdown.
- Vollständige Operator-UX über Streamlit, der Endkunde schaltet Services per Klick, sieht Live-Status und Live-Logs, ohne CLI je gesehen zu haben.
- Modular erweiterbar, neue Workflow-Typen sind ein neues Modul gegen die existierende Coordination- und Reporting-Infrastruktur, ohne Eingriff in den Core.
Diese Leistung anfragen
Browser-Automation auf Production-Niveau
Multi-Worker, Crash-Recovery, CDP-basierte Auth, die Architektur, die hier 17.461 LOC trägt. Adaptierbar auf Ihre Workflows.
Weitere Projekte

AWS Kostenoptimierung
65 % weniger AWS-Kosten (3.850 $ → 1.330 $ / Monat) durch sicheren Rückbau einer Legacy-Plattform, Zero Downtime.

Book Lister AI
Desktop-App, die gebrauchte Bücher in unter 30 Sekunden scannt, per Gemini-Vision erfasst, live bepreist und bei eBay listet, +400 % Durchsatz.

Microsoft Shopping Feed Pipeline
Vollautomatischer täglicher Sync großvolumiger Affiliate-Feeds (Connexity, Shopping24) ins Microsoft Merchant Center, OOM-sicher, chunked-Upload, 100 % konform.