Кейс · Браузерная автоматизация
Multi-Process Browser Automation Framework
Python-фреймворк на 17k LOC для параллельных отказоустойчивых browser-воркфлоу, race-safe координация воркеров, cross-process crash-bridge, per-phase таймауты и полный operator-UX через Streamlit.
- 0
- строк production-кода на Python
- 0+
- pytest-тестов, CI на каждый push
- 0
- модулей, без циклических импортов
Задача
Частному клиенту требовался постоянно работающий backend для browser-автоматизации. Требования с самого начала были инженерными, а не feature-ориентированными:
- Несколько параллельных browser-сессий, чисто изолированных друг от друга.
- Subprocess-архитектура, крах одной сессии не должен ронять другие, а зависший воркфлоу не должен блокировать всё дерево процессов.
- Полная наблюдаемость, каждый переход фазы логирует свой статус, каждый crash несёт уникальный phase-marker.
- Operator-UX через дашборд, а не через CLI, конечный пользователь это клиент, не разработчик.
- 100 % type-hinting, чёткое разделение слоёв, полный pytest-сетап с GitHub Actions CI с первого дня.
Тривиально это не на Windows: параллельные Chrome-инстансы, минное поле race-conditions (port-коллизии при динамической CDP-аллокации, profile-locks в user-data-dir, zombie-процессы при Streamlit-restart). А subprocess, который умирает раньше своего собственного crash-handler, без защитного механизма означает молча потерянный отчёт об ошибке, именно тот класс багов, которые в продакшне не обнаруживаются по шесть недель.
Решение
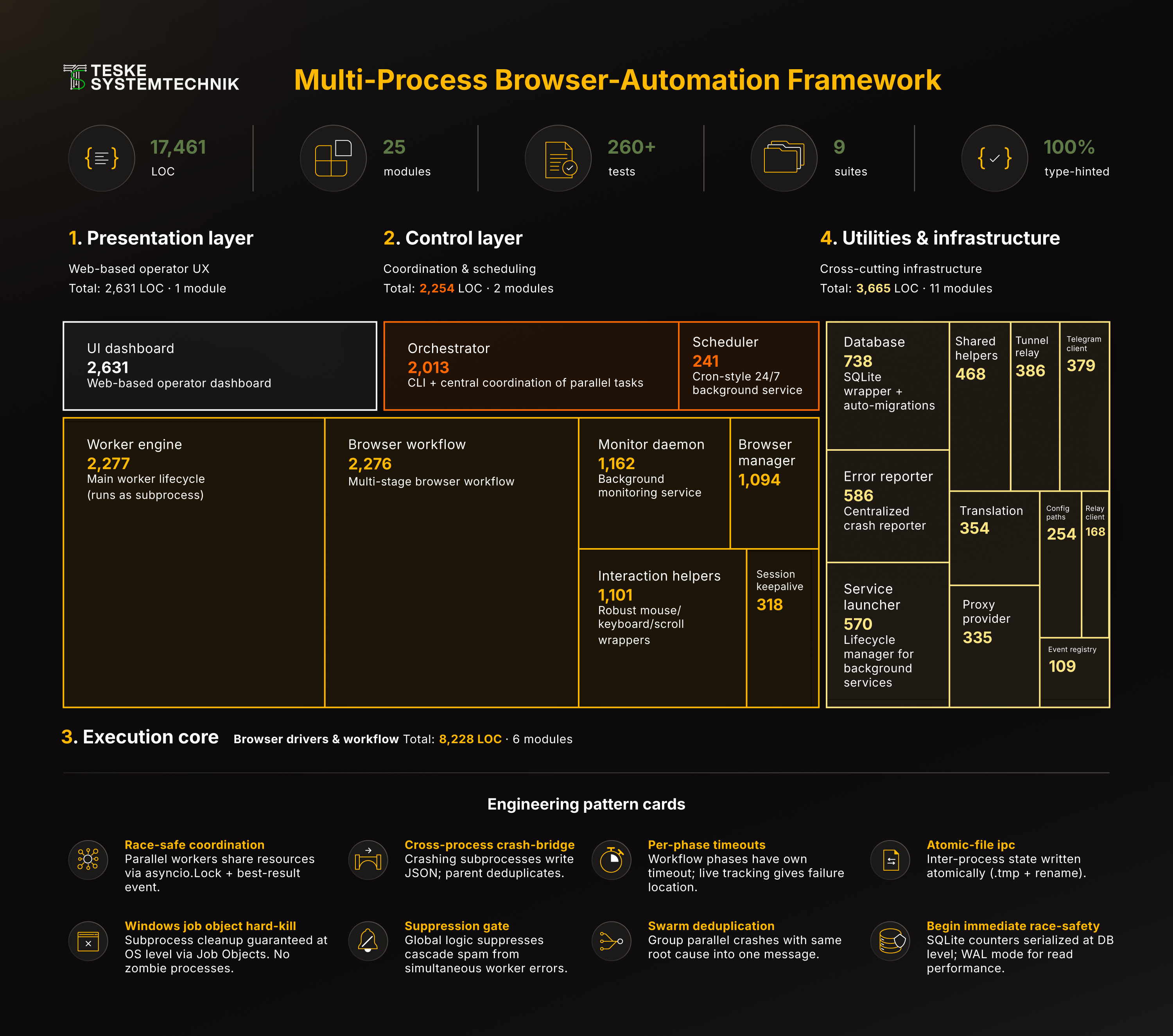
Результат, Python-кодбаза на 17 461 LOC в 25 чисто модуляризованных файлах, полностью с типами, организованная в три чётко развязанных слоя:
Presentation → Streamlit-UI
Control → Scheduler + CLI-оркестратор
Execution → Browser-воркеры (как subprocesses)Cross-layer-коммуникация идёт исключительно через SQLite и атомарно записанные JSON-файлы; ни один воркер никогда не импортирует другого.
- Race-safe координация мультиворкеров. При N параллельных asyncio-задачах воркеры делят общий round-robin на базе
asyncio.Lock: только один воркер за раз выполняет дорогой discovery-шаг, остальные ждут на локе и забирают результат из shared-dict. Сокращает исходящий output вдвое без потери скорости и предотвращает дублирование одной и той же операции всеми воркерами параллельно. - Best-result агрегация с coordinated cancellation. Как только один воркер достигает целевого результата, срабатывает
asyncio.Event, и watchdog-задача вызываетtask.cancel()на всех sibling-задачах. ЧистаяCancelledError-пропагация вместо polling. Дополнительно класс-глобальный_completed_jobs-set подавляет поздние отчёты от отменённых задач, никакого notification-спама, даже когда 10 sibling-ов одновременно проходят свой cleanup-путь. - Subprocess-изоляция на Windows-уровне. Каждый воркер получает полностью изолированный Chrome-инстанс: race-safe port-аллокация через socket-bind (
_PortLockдержит порт зарезервированным, пока Chrome его не примет, никакой TOCTOU-race), собственный user-data-dir (chrome_<uuid>), собственный crash-dump-путь, собственная CDP-сессия. Никаких разделяемых ресурсов, никаких lock-конфликтов между параллельными сессиями, никаких утечек browser-state. - CDP-based auth-конфигурация. Вместо классического Manifest-V2 browser-extension auth-конфигурация работает напрямую через Chrome DevTools Protocol через
Fetch.authRequired. Auth-события автоматически распространяются на popup-страницы черезcontext.on("page", …)-handler. Лёгкий класс заменяет традиционный extension-workaround со значительно меньшей surface area. - Cross-process crash-file-bridge. Воркеры запускаются как subprocesses, спавнятся scheduler-ом через
subprocess.Popen. При краше subprocess пишет структурированный JSON вdata/crashes/job_<id>_<ts>.jsonИ параллельно пытается прямую Telegram-нотификацию. Scheduler читает файл после subprocess-exit, дедуплицирует с уже отправленной нотификацией, дополняет недостающие сообщения или тихо удаляет файл, если всё уже было отчитано. Глобальныйsys.excepthookкак last line of defence гарантирует: ни один crash не теряется, даже если subprocess умирает так рано, что его собственный crash-handler уже не запускается. - Per-phase таймауты с live-phase tracking. Каждая фаза воркфлоу выполняется в выделенном
asyncio.timeout()-блоке; каждая фаза обновляет центральный context-объект текущим sub-step. При краше в Telegram-отчёте указано точно, в какой фазе какого воркера произошёл сбой, не «где-то в main()», а «4/6 add_step: конкретный UI-элемент X». Время на дебаг падает с «сначала шерстить логи» до «сразу к нужной функции». - Типизированная иерархия ошибок + swarm-deduplication. Отдельный exception-класс на каждый failure-mode (
ProxyError,NavigateError,SessionExpiredError, …), у каждого собственная recovery-политика (закрыть браузер vs. оставить открытым, retry с другим прокси, hard-fail). Когда 10 воркеров крашатся параллельно с одним и тем же root-cause,report_grouped_errorsгруппирует сообщения по (тип exception, первый stackframe) и шлёт одно агрегированное Telegram-сообщение с worker-ID и затронутыми фазами, никаких 10 redundant пингов. - SQLite с WAL + BEGIN IMMEDIATE для race-safety. Counter и state в таблицах обновляются в read-modify-write-транзакциях. При N параллельных воркерах, инкрементящих counter одновременно, наивная UPDATE-counter-логика инкрементировала бы counter на 1 вместо N,
BEGIN IMMEDIATEсериализует апдейты корректно и предотвращает race на уровне SQLite, до того как она вообще достигнет Python. Плюс WAL-режим + 64 МБ кэша + 256 МБ mmap для read-производительности под параллельным write-давлением. Авто-миграции на первом connect, с pytest-тестами, верифицирующими каждую миграцию по отдельности. - Atomic file IPC. Все inter-process state-файлы (job-status snapshots, live-state, run-reports) пишутся атомарно, пишем в
.tmp, потомos.rename(). Ни один воркер никогда не читает наполовину записанный JSON, даже при конкурентном доступе из нескольких subprocesses. POSIX-семантика, работает и на Windows со времёнPath.replace(). - Логи с датированными версиями.
logs/<DD-MM-YYYY>/{chrome,traces,screenshots,…}/, каждая фаза каждого воркера производит чётко атрибутированные артефакты (Chrome-stdout, Playwright-trace, failure-screenshot). При production-инциденте черезls logs/23-03-2026/screenshots/за пять секунд находишь точную failure-фазу каждого затронутого воркера, плюс полный Playwright-trace, готовый к replay в browser-trace-viewer. - Streamlit operations UI с Windows hard cleanup. Multi-page дашборд с service-lifecycle (старт/стоп/перезапуск всех подсистем), DB-CRUD, live-логи, EN/IT-локализация на 300+ string-pairs. Streamlit на Windows капризен, process-tree cleanup не гарантирован при shutdown, дочерние процессы становятся zombie. Решено через Windows Job Object с
JOB_OBJECT_LIMIT_KILL_ON_JOB_CLOSE: каждый subprocess при spawn привязывается к job-handle, а при exit Streamlit ОС автоматически терминирует всех потомков каскадно. Работает даже при hard-kill через Task Manager, никаких остаточных browser-процессов. - Централизованный Telegram-reporter. Единственный
ErrorReporter-класс как single entry point для всех нотификаций. Fire-and-forget by contract: никогда не бросает exception, никогда не блокируется дольше HTTP-roundtrip, тихо проваливается при connection-ошибках (Windows 10054 ConnectionReset, …) и retryится со свежей session. Direct connection без proxy (session.trust_env = False), чтобы system-proxy-vars не убивали отчёты молча, плюс глобальная suppression-логика против notification-storms.
Инженерные решения и отказоустойчивая архитектура
Надёжность не подлежала обсуждению, система работает 24/7 без присмотра, конечный пользователь, не разработчик:
- 9 pytest test-suites с GitHub Actions CI. Database-миграции (идемпотентные, исполняемые многократно), error-reporter (260+ тестов включая suppression-логику и crash-file-roundtrip), coordination-паттерны, proxy-слой, shared-helpers, config-resolution, всё валидируется автоматически на каждом push против Ubuntu Python 3.13. Migration-баги ловятся до деплоя, а не в рантайме.
- Строгое разделение слоёв без циклических импортов. Presentation-слой импортирует только Control-слой; Control-слой, только Execution-слой + utils. Каждый subprocess можно поднять standalone, без установленного Streamlit, релевантно для CI-runs и debug-сессий без UI-overhead.
- Singleton path resolution. Класс
PATHS-singleton с auto-root detection (идёт вверх в поисках marker-файлов вроде.git,.env,requirements.txt) и автоматическим созданием директорий на property-access. Код, вызванный из любого working-directory, всегда находит одни и те же абсолютные пути, ни одногоos.path.join(os.path.dirname(__file__), …)во всей кодбазе. - Dataclass-first domain model. Все workflow-входы и -выходы, dataclasses с type-hints, validation-логикой и чистыми
from_dict/to_dict-roundtrips. Чистые интерфейсы между слоями, IDE-autocomplete работает, рефакторинги поднимают compile-time ошибки вместо runtime AttributeErrors. - Test-first для IPC-критичных компонентов. Crash-file-bridge, suppression-gate и aggregator-логика, самые рискованные места: они работают именно тогда, когда всё остальное сломалось. Test-suite соответственно плотный: собственный
_clear_*-fixture-pattern сбрасывает класс-глобальный state между тестами, у каждого edge-case (subprocess crashed ДО crash-file-write, crash-file без Telegram-флага, Telegram после crash-file, оба параллельно) есть явный test-case. - Dependency-injection-слой для тестов. Каждая внешняя зависимость (DB, Telegram, proxy-provider, filesystem) сидит за тонким интерфейсом, который в тестах заменяется на in-memory-эквивалент. SQLite-тесты, однако, работают против реальной SQLite-DB в pytest-
tmp_path, не против mock, migration-баги mocks системно не выявили бы.
Распределение объёма всей кодбазы по слоям Presentation, Control, Execution Core и Utility, Execution Core (8 228 LOC) визуально доминирует как самый большой блок, а utility-слой показывает модульность через 11 небольших helper-модулей.
Результат
- 17 461 LOC production-Python в 25 чисто модуляризованных файлах, чистое разделение слоёв, никаких циклических импортов, каждая стадия запускается standalone.
- 260+ pytest-тестов с GitHub Actions CI на каждом push, migration-баги, IPC race-conditions и suppression-логика отлавливаются до деплоя.
- Cross-process crash-bridge, ни один crash не теряется, даже при subprocess-смерти до собственного crash-handler.
- Race-safe координация между N параллельных browser-воркеров на Windows, никаких port-коллизий, profile-locks, zombie-процессов при shutdown.
- Полный operator-UX через Streamlit, конечный клиент переключает сервисы кликом, видит live-статус и live-логи, никогда не открывая CLI.
- Модульная расширяемость, новые workflow-типы, это новый модуль против существующей coordination- и reporting-инфраструктуры, без вмешательства в core.
Заказать такую услугу
Browser-automation на production-уровне
Multi-worker, crash recovery, CDP-based auth, архитектура, которая держит здесь 17 461 LOC. Адаптируется под ваши workflow.
Другие проекты

Оптимизация расходов AWS
Снижение расходов на AWS на 65 % (с $3 850 до $1 330 в месяц) за счёт безопасного вывода из эксплуатации legacy-платформы, без простоев.

Book Lister AI
Настольное приложение: сканирует подержанные книги за 30 секунд, распознаёт через Gemini Vision, устанавливает цену в реальном времени и публикует на eBay, +400 % к производительности.

Microsoft Shopping Feed Pipeline
Полностью автоматизированная ежедневная синхронизация крупнообъёмных партнёрских фидов (Connexity, Shopping24) в Microsoft Merchant Center, OOM-безопасно, chunked-загрузка, 100 % соответствие.