Case Study · Legacy-Migration & Data Recovery
Legacy-DB Reverse Engineering & Migration
Daten aus einer 1,2 GB großen, passwortgeschützten Hersteller-Datenbank befreit und ins neue System migriert. Vollständig validiert und auditierbar.

- 1,47 Mio
- Bauteile aus der Alt-Datenbank befreit
- 0
- Schaltbilder ins neue Format konvertiert
- 0 Verstöße
- gegen die Validierungsregeln, voll auditierbar
Die Herausforderung
Der Kunde betreibt das After-Market-Geschäft für Ersatzteile eines internationalen Tier-1 Baumaschinenherstellers und besitzt eine gültige Lizenz für dessen Wartungs-Datenbank, eine 1,2 GB große, passwortgeschützte MS-Access-Datei (.mdb) aus den frühen 2000ern. Die rechtmäßig erworbenen Daten sollen in das neue Warenwirtschaftssystem des Kunden überführt werden. Drei Mauern stehen dem im Weg.
Erstens: die ursprünglichen Konfigurationsparameter der Datenbank, insbesondere die Zugangsdaten, sind im Lauf der Jahre intern verloren gegangen, und das alte Hersteller-Tool öffnet die DB zwar im Hintergrund, exportiert aber keine Rohdaten.
Zweitens: das Schema. Rund 30 verflochtene Tabellen mit kryptischen Spaltennamen, n:m-Relationen zwischen Büchern und Verkaufsmodellen, Bauteilnamen verteilt über drei Tabellen plus ein Sprachfeld, nichts davon ohne strukturelle Analyse lesbar.
Drittens: rund 82.000 Schaltbilder im obskuren DjVu-Format der frühen 2000er, das das neue System nicht rendert.
Und das Ganze in einer Größenordnung (~1,9 Mio. Rohzeilen), die Excel ohne Murren bei 1.048.576 Zeilen abschneiden würde, was de facto die halbe Maschinenflotte unterschlagen hätte. Aufgabe: alle drei Mauern einreißen und den vollständigen, lizenzierten Datenbestand sauber in das neue System überführen.
Die Umsetzung
- Forensische Wiederherstellung verlorener Zugangsdaten. Statt das alte Wartungs-Tool zur Blackbox zu erklären, wird die Systemumgebung des Kunden forensisch analysiert: ein gezielter Scan über das gesamte lokal installierte Verzeichnis (
.exe,.dll,.ini,.cfg,.xml) durchsucht die Konfigurationsdateien und Laufzeit-Artefakte nach den klassischen Indikatoren persistierter Connection-Parameter, Jet-OLEDB-Strings, PWD/UID-Verweise,.mdw-Pfade, mit Kontext-Window um jeden Treffer. Aus den Konfigurations-Resten lassen sich die ursprünglichen Zugangsdaten rekonstruieren, die der Kunde mit seiner Lizenz ohnehin besitzt. Ab da ist die DB viapyodbc+ Microsoft Access Driver direkt auf der Datenebene lesbar. - Strukturelle Schema-Rekonstruktion. Die DB hat keine Doku, keine ER-Diagramme, nur Tabellennamen und Spalten-Codes. Ein Schema-Scanner zieht aus jeder Tabelle 10-Zeilen-Samples plus den vollen Spalten-Header und macht damit die Beziehungen zwischen den ~30 Tabellen sichtbar, welche Tabelle hält Ersatznummern, welche das Bild-File-ID, wo liegen die Sprachvarianten der Bauteilnamen. Das ist die Grundlage für den späteren Single-Source-Join. Ergebnis: drei lateral verstreute Quellen für Ersatzteil-Nummern (eine Live-Zuordnungs-Tabelle plus zwei Stammdaten-Tabellen mit historischen Ersetzungen), zwei für Bilddateien (mit Fallback-Kette) und eine sprachgefilterte Quelle für englische Klartextnamen.
- One-Shot Cold-Storage in SQLite. Die gesamte Access-DB wird in einem Take in eine lokale SQLite-Datei geclont, alle Spalten als TEXT (am sichersten gegen die inkonsistente Typisierung der Quelle), in 10k-Häppchen via
fetchmany. Vorteil: ab da läuft jede Auswertung lokal, beliebig oft und ohne ODBC-Overhead, der 1,2-GB-Mahlstein wird zur 400-MB-Read-only-Quelle und ist von der Migrations-Pipeline entkoppelt. - Multi-Table-Join als Single Source of Truth. Eine zentrale Query bündelt das gewonnene Schema-Wissen in einem Statement. Der Bauteile-Katalog joint mit der Buch-zu-Modell-Mapping-Tabelle und der Verkaufsmodell-Tabelle (denn die Wartungsbücher heißen intern anders als die Endprodukt-Modelle), der Figuren-Tabelle (Gruppe / Untergruppe / Bilddatei via
COALESCEals Fallback-Kette), der sprachgefilterten Klartextnamen-Tabelle und einer CTE, die alle Ersatzteil-Beziehungen pro Bauteil mitGROUP_CONCATzu einer kommagetrennten Liste verdichtet. Sichere LEFT JOINs mitIFNULLfangen leere Schlüsselfelder ab, das Zielsystem braucht für jede Zeile ein vollständiges Tupel, kein lückenhaftes. - Self-Healing Part Names. Die Roh-Daten enthielten als „Bauteilname" oft nur den Platzhalter
"PART", reine alphanumerische Codes oder Müll wie"(OPTIONAL)", alles Werte, die ein modernes ERP-/Shop-System sofort als Datenmüll markieren würde. Lösung: ein In-RAM-Wörterbuch aus der englischsprachigen Stammdaten-Tabelle liefert pro Teilenummer den korrekten Klartextnamen. Heuristiken (Mindestlänge 3, kein reiner Code-String, kein „PART"-Platzhalter) entscheiden, wann gelookup-ed wird, bei Treffer wird der Name geheilt, sonst wird der Datensatz alsUNKNOWN_NAME_REQUIRES_CHECKmarkiert und in einer späteren Stage hart gefiltert. Der Heilungsschritt allein rettet zehntausende Zeilen vor dem Müll-Filter. - DjVu → JPG Pipeline mit Multithreading. ~82.000 Schaltbilder lagen im obskuren DjVu-Format vor, ein Format, das das neue System nicht rendern kann und für das es keine moderne Standard-Library gibt. Pipeline:
ddjvu(DjVuLibre) konvertiert jede Datei in ein temporäres PDF, PyMuPDF (fitz) rendert die erste Seite mit 150 DPI in Graustufen als JPG (massiver Speicherplatz-Gewinn ohne Lesbarkeits-Verlust), das Temp-PDF wird sofort gelöscht.ThreadPoolExecutorfährt mitos.cpu_count()Workern. Idempotente Skip-Logik (fertige Targets werden übersprungen) macht den Lauf re-runnable, ein Crash bei Datei 50.000 kostet keine 50.000 Re-Konvertierungen. - System-aware Hyperlinks. Statt nackter Pfade wird jede Image-Zelle als
=HYPERLINK("…\<bildpfad>.jpg", "<bildname>.jpg")geschrieben, ein Format, das vom Zielsystem direkt als klickbarer Bild-Link verstanden wird. Ein rekursiver Index aller JPGs (Dateiname → relativer Pfad) löst die Bilder vor dem Schreiben auf; nicht gefundene Bilder werden defensiv alsMISSING_JPG: <stem>markiert, statt die Spalte still zu verschmutzen oder die Migration abzubrechen. - Iterative Cleanup-Stages mit Audit-Trail. Raw → v2 (Hyperlinks injiziert) → Pristine_v2 (UNKNOWN-Namen + manuell blockierte regionale Sondervarianten entfernt) → Pristine_v3 (String-Cleanup: Semikolons, führende Sonderzeichen, doppelte Leerzeichen) → Final_Delivered (Ersatzteil-Nummern aus den beiden Stammdaten-Quellen nachgeladen, Duplikate vermieden) → Perfect (drei letzte Problemzeilen mit verschmutzter SubGroup entfernt). Jede Stage ist eine eigene Datei und ein eigenes Skript, debugbar, reproduzierbar, mit klarem Audit-Trail. Wer am Ende fragt „warum ist Zeile X nicht im neuen System?", bekommt eine Antwort.
- Strict-Mode Validation gegen das Ziel-Schema. Ein dedizierter Validator prüft die finale CSV gegen einen 5-Regel-Schema-Vertrag, der 1:1 dem entspricht, was das Zielsystem akzeptiert: Header (exakt 10 Spalten in fester Reihenfolge), Pflichtfelder (Buch + Teilenummer gesetzt), keine illegalen Steuerzeichen (Regex
\x00-\x1f), Format Teilenummer (keine Klammern), Format Teilename (uppercase, kein führendes Sonderzeichen, kein UNKNOWN_NAME), Format Image_File (=HYPERLINK+.jpgoder explizitesMISSING_JPG). Ergebnis nach mehreren Iterationen: 1.473.210 Zeilen, null Regelverstöße. Jeder Verstoß landet in einer Log-Datei mit Zeilennummer + Buch + Teilenummer + Begründung, surgical, nicht „irgendwas ist kaputt". - Trust-By-Transparenz. Zwei separate Reports werden mitgeliefert. Coverage-Report: alle 386 Master-Bücher aus der Quell-DB mit Mapping zum Verkaufsmodell und Zeilenzahl in der finalen CSV, der Kunde sieht für jedes einzelne Buch, ob und wie viele Bauteile in das neue System überführt wurden. Trash-Analysis: alle 470.276 weggefilterten Zeilen mit Begründung, fehlender englischer Name, manuell geblockte regionale Sondervariante, Teilenummer unter vier Zeichen, sonstiger Bereinigungs-Filter. Der Kunde bekommt nicht nur die Migration, sondern jede einzelne Filter-Entscheidung dokumentiert.
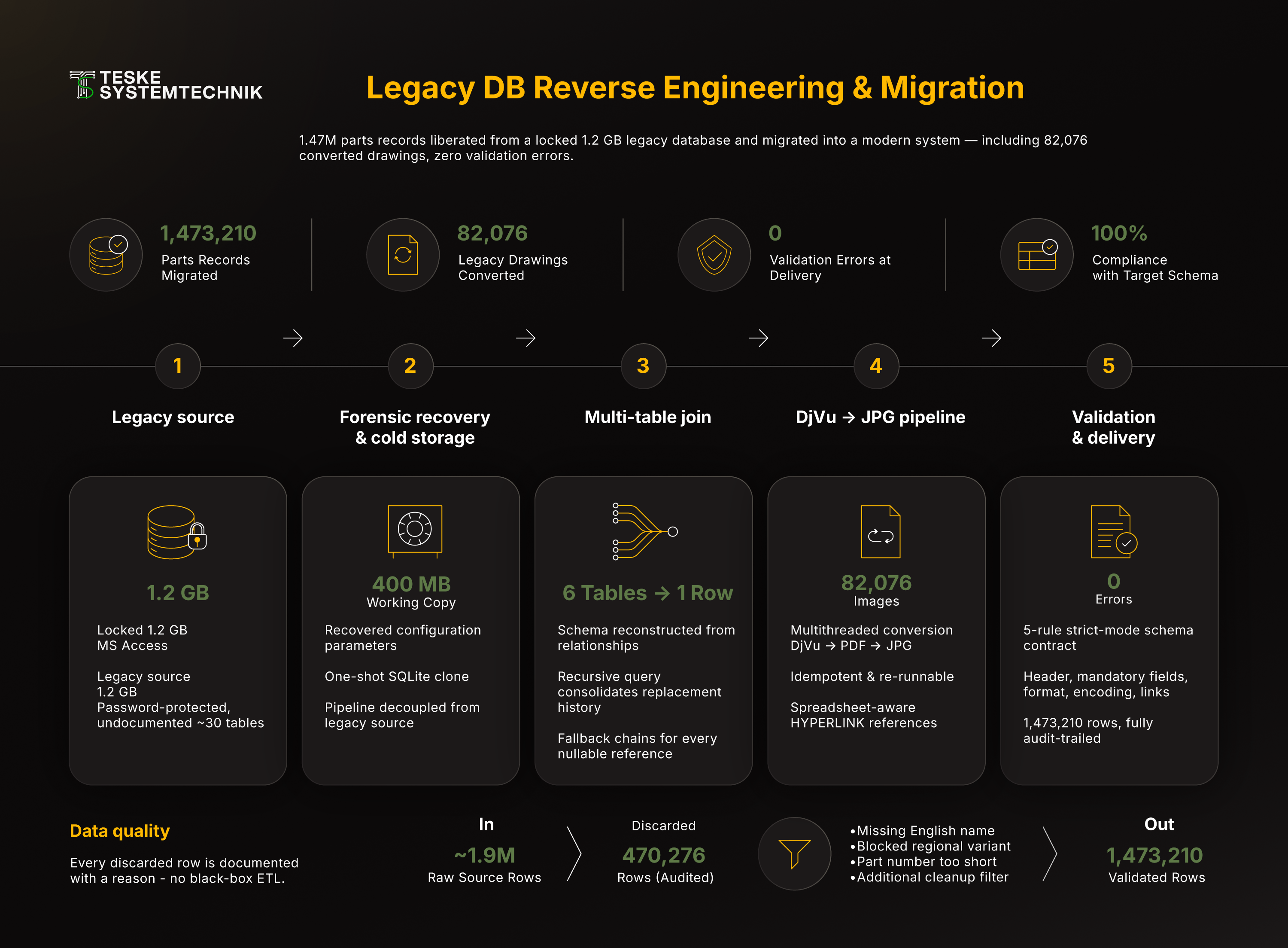
Das Diagramm zeigt den vollständigen Migrationsfluss: von der forensischen Konfigurationsdaten-Wiederherstellung über die geöffnete 1,2-GB MS-Access-Quelldatenbank, den SQLite-Klon, die zentrale Multi-Table-Join-Query und die parallele DjVu-zu-JPG-Konvertierungs-Pipeline bis hin zur Hyperlink-Injektion und der Strict-Mode-Validierung gegen das Schema des neuen Zielsystems.
Das Ergebnis
- Hersteller-Lock-in aufgehoben. Eine 1,2-GB-Legacy-Datenbank, die der Kunde rechtmäßig lizenziert hatte, aber faktisch nicht mehr nutzen konnte, wurde forensisch erschlossen, ihr Schema strukturell rekonstruiert und der vollständige Datenbestand in seinen Besitz überführt, ohne weitere Abhängigkeit vom alten Wartungs-Tool.
- 1.473.210 migrierte Bauteil-Datensätze über 339 Verkaufsmodelle (aus 386 Master-Büchern inkl. n:1-Mappings, wo ein Buch mehrere Modellvarianten abdeckt), bereit zur Ingestion in das neue System.
- ~82.000 Original-Schaltbilder vom alten DjVu-Format in modernes JPG konvertiert und per
=HYPERLINKreferenziert, defensiv markiert wo die Konvertierung fehlte, statt das Delivery zu blockieren. - Null Regelverstöße in der Final-CSV gegen einen 5-Regel-Strict-Mode-Validierungs-Vertrag, das Akzeptanzkriterium des Zielsystems war binär, das Ergebnis ist binär.
- 1,2 GB Legacy-MDB → 400 MB SQLite (Cold-Storage) → 274 MB CSV (Migrations-Lieferung). Volle Datenhoheit jenseits des proprietären Hersteller-Tools, in einem Format, das jedes moderne ERP-, Shop- oder BI-System versteht.
- Vollständiger Audit-Trail über jede einzelne der 470.276 verworfenen Roh-Zeilen plus über jedes der 386 Bücher, kein Black-Box-ETL, sondern ein Migrations-Vertrag, den der Kunde Zeile für Zeile nachvollziehen kann.
- Excel-Hard-Limit umschifft. Die CSV bleibt streamfähig, das neue System ingestet sequenziell, nichts wird stillschweigend bei 1.048.576 Zeilen gekappt, wie es bei einem naiven Excel-Re-Save passiert wäre.
Diese Leistung anfragen
Legacy-Datenmigration & Reverse Engineering
Eine alte Datenbank, ein verschwundener Hersteller, ein neues Zielsystem, das gleiche Verfahren wie hier, mit Schema-Doku, Strict-Mode-Regeln und Audit-Trail. Für Ihre Migration verfügbar.
Weitere Projekte

AWS Kostenoptimierung
65 % weniger AWS-Kosten (3.850 $ → 1.330 $ / Monat) durch sicheren Rückbau einer Legacy-Plattform, Zero Downtime.

Book Lister AI
Desktop-App, die gebrauchte Bücher in unter 30 Sekunden scannt, per Gemini-Vision erfasst, live bepreist und bei eBay listet, +400 % Durchsatz.

Microsoft Shopping Feed Pipeline
Vollautomatischer täglicher Sync großvolumiger Affiliate-Feeds (Connexity, Shopping24) ins Microsoft Merchant Center, OOM-sicher, chunked-Upload, 100 % konform.