Кейс · Миграция legacy и восстановление данных
Реверс-инжиниринг и миграция legacy-БД
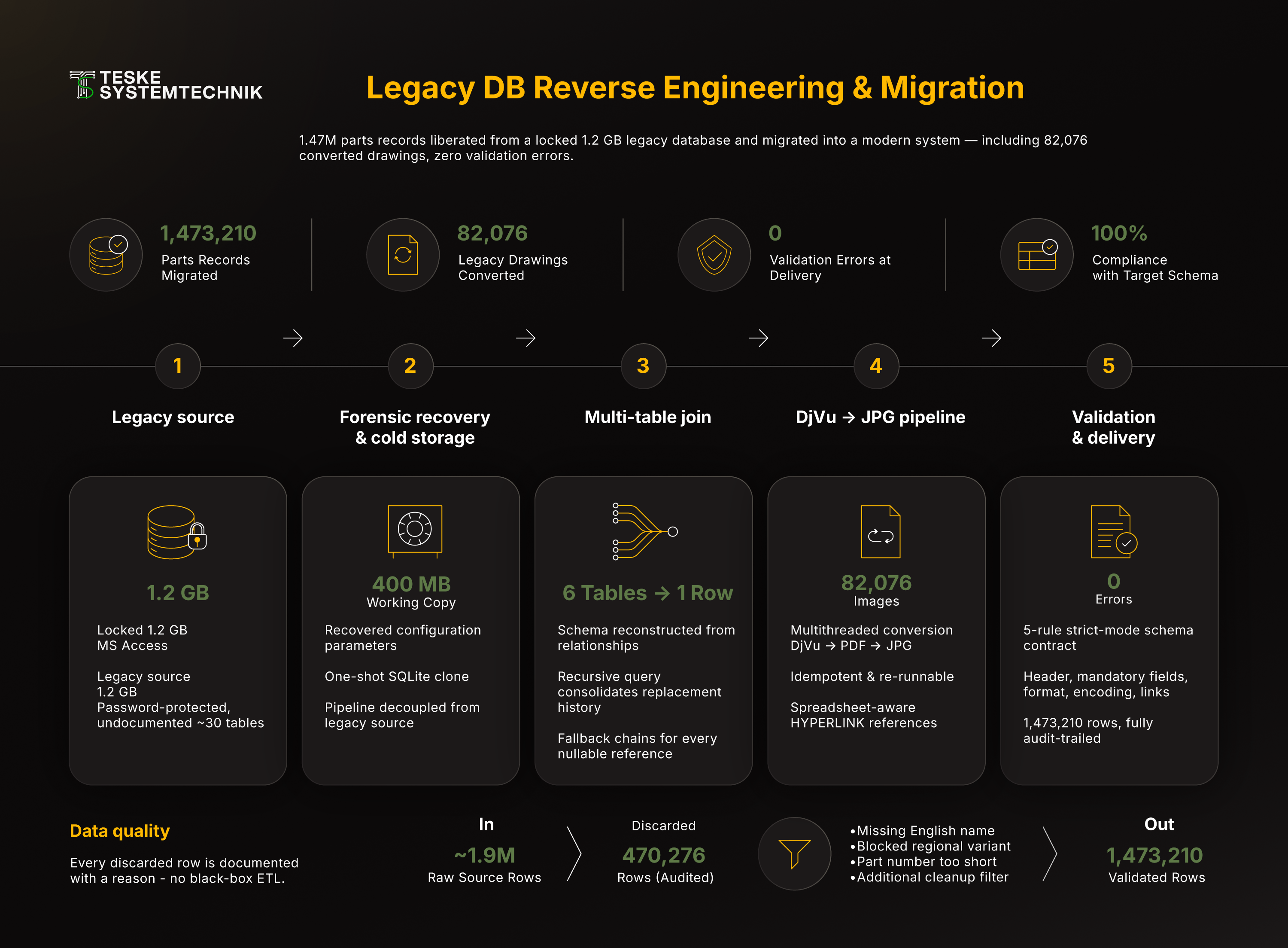
1,47 млн деталей извлечены из защищённой паролем БД производителя объёмом 1,2 ГБ и перенесены в новую систему клиента, включая 82 076 конвертированных схем, валидация с нулём нарушений, полностью аудируемо.

- 1,47 млн
- компонентов извлечено из старой базы
- 0
- схем преобразовано в новый формат
- 0 нарушений
- правил валидации, полностью аудируемо
Задача
Заказчик, поставщик запчастей на вторичном рынке для одного из международных производителей строительной техники Tier-1, владеет действующей лицензией на его сервисную базу данных, защищённый паролем файл MS Access (.mdb) объёмом 1,2 ГБ из начала 2000-х. Легально приобретённые данные нужно перенести в новую систему товарного учёта клиента. На пути, три стены.
Первая: исходные параметры конфигурации БД, в первую очередь учётные данные доступа, за годы внутри организации потеряны, а старый инструмент производителя хоть и открывает БД в фоновом режиме, сырых данных не экспортирует.
Вторая: схема. Около 30 переплетённых таблиц с криптическими именами столбцов, n:m-связи между книгами и моделями продаж, имена деталей разнесены по трём таблицам плюс языковое поле, ничего из этого без структурного анализа не читается.
Третья: около 82 000 схем в малопонятном формате DjVu начала 2000-х, который новая система не отображает.
И всё это в масштабе (~1,9 млн сырых строк), который Excel молча обрезал бы на 1 048 576 строк, фактически потеряв половину парка машин. Задача: снести все три стены и аккуратно перенести полный лицензированный объём данных в новую систему.
Реализация
- Криминалистическое восстановление утерянных учётных данных. Вместо того чтобы объявлять старый сервисный инструмент чёрным ящиком, локальная среда клиента анализируется криминалистически: целевое сканирование всего установленного каталога (
.exe,.dll,.ini,.cfg,.xml) ищет в конфиг-файлах и runtime-артефактах классические индикаторы сохранённых параметров подключения, Jet-OLEDB-строки, ссылки PWD/UID, пути к.mdw, с контекстным окном вокруг каждого совпадения. По остаткам конфигураций восстанавливаются исходные учётные данные, которыми клиент и так владеет в рамках лицензии. С этого момента БД читается напрямую черезpyodbc+ Microsoft Access Driver на уровне данных. - Структурная реконструкция схемы. У БД нет ни документации, ни ER-диаграмм, только имена таблиц и коды столбцов. Сканер схемы извлекает из каждой таблицы 10-строчные сэмплы плюс полный заголовок и таким образом делает связи между ~30 таблицами видимыми, какая таблица хранит замены номеров, какая ID файлов изображений, где лежат языковые варианты имён деталей. Это основа для последующего Single-Source-Join. Результат: три латерально разнесённых источника номеров запчастей (одна live-таблица соответствий плюс две справочные таблицы с историческими заменами), два, для файлов изображений (с цепочкой fallback) и один отфильтрованный по языку источник для англоязычных читаемых имён.
- One-Shot Cold-Storage в SQLite. Вся Access-БД клонируется одним заходом в локальный SQLite-файл, все колонки как TEXT (надёжнее всего против непоследовательной типизации источника), пакетами по 10k через
fetchmany. Преимущество: с этого момента любая аналитика выполняется локально, сколько угодно раз и без ODBC-оверхеда, 1,2-ГБ жернов превращается в 400-МБ read-only источник и отвязывается от миграционного pipeline. - Multi-Table-Join как Single Source of Truth. Один центральный запрос объединяет всё накопленное знание о схеме в одной инструкции. Каталог деталей джойнится с таблицей маппинга «книга → модель» и таблицей моделей продаж (потому что сервисные книги внутри называются иначе, чем конечные модели), таблицей фигур (группа / подгруппа / файл изображения через
COALESCEкак fallback-цепочку), отфильтрованной по языку таблицей читаемых имён и CTE, который черезGROUP_CONCATсворачивает все связи замен по каждой детали в список через запятую. Безопасные LEFT JOIN сIFNULLловят пустые ключи, целевая система требует на каждую строку полного кортежа, а не дырявого. - Self-Healing имён деталей. Сырые данные часто содержали в качестве «имени детали» только заглушку
"PART", чисто буквенно-цифровые коды или мусор вроде"(OPTIONAL)", всё это современная ERP-/shop-система немедленно пометила бы как мусорные данные. Решение: словарь in-RAM из англоязычной справочной таблицы возвращает по номеру детали корректное читаемое имя. Эвристики (минимальная длина 3, не чистый код, не «PART»-заглушка) определяют, когда выполнять lookup, при попадании имя «лечится», иначе запись помечается какUNKNOWN_NAME_REQUIRES_CHECKи жёстко фильтруется на более поздней стадии. Один шаг лечения спасает десятки тысяч строк от мусорного фильтра. - DjVu → JPG pipeline с многопоточностью. ~82 000 схем лежали в малопонятном формате DjVu, формате, который новая система не рендерит и для которого нет современной стандартной библиотеки. Pipeline:
ddjvu(DjVuLibre) конвертирует каждый файл во временный PDF, PyMuPDF (fitz) рендерит первую страницу с 150 DPI в градациях серого как JPG (массивная экономия места без потери читаемости), временный PDF тут же удаляется.ThreadPoolExecutorзапускается сos.cpu_count()воркерами. Идемпотентная skip-логика (готовые цели пропускаются) делает прогон повторно запускаемым, крах на файле 50 000 не стоит 50 000 повторных конвертаций. - System-aware гиперссылки. Вместо голых путей каждая ячейка изображения записывается как
=HYPERLINK("…\<путь_к_изображению>.jpg", "<имя_изображения>.jpg"), формат, который целевая система понимает напрямую как кликабельную ссылку на изображение. Рекурсивный индекс всех JPG (имя файла → относительный путь) разрешает изображения перед записью; ненайденные изображения помечаются защитно какMISSING_JPG: <stem>, вместо тихого засорения колонки или прерывания миграции. - Итеративные стадии очистки с audit-trail. Raw → v2 (внедрены гиперссылки) → Pristine_v2 (удалены имена UNKNOWN + вручную заблокированные региональные спец-варианты) → Pristine_v3 (string-cleanup: точки с запятой, ведущие спецсимволы, двойные пробелы) → Final_Delivered (номера запчастей подгружены из обоих справочных источников, дубликаты устранены) → Perfect (удалены три последние проблемные строки с грязным SubGroup). Каждая стадия, отдельный файл и отдельный скрипт, отлаживаемо, воспроизводимо, с чётким audit-trail. Кто в конце спросит «почему строки X нет в новой системе?», получит ответ.
- Strict-Mode-валидация против целевой схемы. Выделенный валидатор проверяет финальный CSV против контракта схемы из 5 правил, 1:1 соответствующего тому, что принимает целевая система: заголовок (ровно 10 столбцов в фиксированном порядке), обязательные поля (книга + номер детали заполнены), отсутствие недопустимых управляющих символов (regex
\x00-\x1f), формат номера детали (без скобок), формат имени детали (uppercase, без ведущего спецсимвола, без UNKNOWN_NAME), формат Image_File (=HYPERLINK+.jpgлибо явныйMISSING_JPG). Результат после нескольких итераций: 1 473 210 строк, ноль нарушений. Каждое нарушение попадает в лог-файл с номером строки + книга + номер детали + обоснование, surgical, а не «что-то сломано». - Trust-By-Transparency. К поставке прилагаются два отдельных отчёта. Coverage-отчёт: все 386 master-книг из исходной БД с маппингом на модель продаж и количеством строк в финальном CSV, клиент видит для каждой отдельной книги, сколько и какие детали перенесены в новую систему. Trash-Analysis: все 470 276 отфильтрованных строк с обоснованием, отсутствие английского имени, заблокированный вручную региональный спец-вариант, номер детали короче четырёх символов, прочий фильтр очистки. Клиент получает не просто миграцию, а каждое отдельное решение фильтра, задокументированным.
Диаграмма показывает полный поток миграции: от криминалистического восстановления конфиг-данных через открытую исходную 1,2-ГБ MS-Access-БД, SQLite-клон, центральный multi-table-join-запрос и параллельный pipeline DjVu→JPG до инжекции гиперссылок и Strict-Mode-валидации против схемы новой целевой системы.
Результат
- Зависимость от производителя снята. 1,2-ГБ legacy-БД, которой клиент владел по лицензии, но фактически больше не мог использовать, криминалистически вскрыта, её схема структурно реконструирована, а полный объём данных перенесён в его собственность, без дальнейшей зависимости от старого сервисного инструмента.
- 1 473 210 перенесённых записей деталей по 339 моделям продаж (из 386 master-книг включая n:1-маппинги, где одна книга покрывает несколько вариантов модели), готовы к загрузке в новую систему.
- ~82 000 оригинальных схем сконвертированы из старого DjVu в современный JPG и проставлены через
=HYPERLINK, там, где конвертация не удалась, проставлены защитные маркеры, а не блокировка поставки. - Ноль нарушений в финальном CSV против контракта Strict-Mode-валидации из 5 правил, критерий приёмки целевой системы был бинарным, и результат бинарный.
- 1,2 ГБ legacy-MDB → 400 МБ SQLite (cold-storage) → 274 МБ CSV (миграционная поставка). Полный суверенитет над данными вне проприетарного инструмента производителя, в формате, который понимает любая современная ERP-, shop- или BI-система.
- Полный audit-trail по каждой из 470 276 отбракованных сырых строк плюс по каждой из 386 книг, не чёрный ящик ETL, а миграционный контракт, который клиент может проследить строка за строкой.
- Hard-лимит Excel обойдён. CSV остаётся пригоден к стримингу, новая система загружает данные последовательно, ничего не обрезается молча на 1 048 576 строк, как это произошло бы при наивном Excel-Re-Save.
Заказать такую услугу
Миграция legacy-данных и реверс-инжиниринг
Старая база, исчезнувший вендор, новая целевая система, тот же процесс, что и здесь, с документацией схемы, strict-mode правилами и audit trail. Доступно для вашей миграции.
Другие проекты

Оптимизация расходов AWS
Снижение расходов на AWS на 65 % (с $3 850 до $1 330 в месяц) за счёт безопасного вывода legacy-платформы, без простоев.

Book Lister AI
Настольное приложение: сканирует подержанные книги за 30 секунд, распознаёт через Gemini Vision, устанавливает цену в реальном времени и публикует на eBay, +400 % к производительности.

Microsoft Shopping Feed Pipeline
Полностью автоматизированная ежедневная синхронизация крупнообъёмных партнёрских фидов (Connexity, Shopping24) в Microsoft Merchant Center, OOM-безопасно, chunked-загрузка, 100 % соответствие.